Delivery Pipeline — это способ разделить сборку на этапы. С каждым этапом возрастает уверенность в качестве сборки, но, обычно, каждый последующий этап выполняется медленнее предыдущего. Я бы назвал эту практику квинтэссенцией принципов и практик непрерывной интеграции и непрерывной поставки, их физическое воплощение. Но, любая новая практика переосмысливает предыдущие и привносит нечто новое, иначе в ней бы не было смысла.
Сколько бы ни было у меня проектов по созданию совместно с клиентом Delivery Pipeline’ов, часто они идут по такому сценарию:
- Создание модели потока создания ценности
- Создание «скелета» Delivery Pipeline’а
- Автоматизация
- Процесса сборки и развертывания
- Выполнения юнит-тестов и анализа кода
- Приемочного тестирования
- Выхода в релиз
В данном случае подразумеваем, что CI/CD-фреймворк уже есть и что артефакты продукта находятся под контролем версий.
Создание модели потока создания ценности
Сложность модели потока создания ценности сильно зависит от стадии разработки продукта.
Для нового продукта обычно моделировать особо нечего. Нужно начинать разработку, так что берем простейшую структуру за основу и приступаем (пример для Jenkins).
pipeline {
agent any
stages {
stage('Build') {
steps {
//
}
}
stage('Test') {
steps {
//
}
}
stage('Deploy') {
steps {
//
}
}
}
}Если процесс уже как-то идет, то без моделирования не обойтись. В противном случае есть риск потерять важный шаг или не заложить, что, например, тестирование должно выполняться параллельно на пяти тестовых стендах с разными операционными системами. Дополнительное преимущество в том, что модель явно показывает шаги Pipeline, — появляется возможность создания стратегии автоматизации и появляется основа для взаимодействия между различными людьми, вовлеченными в процесс.
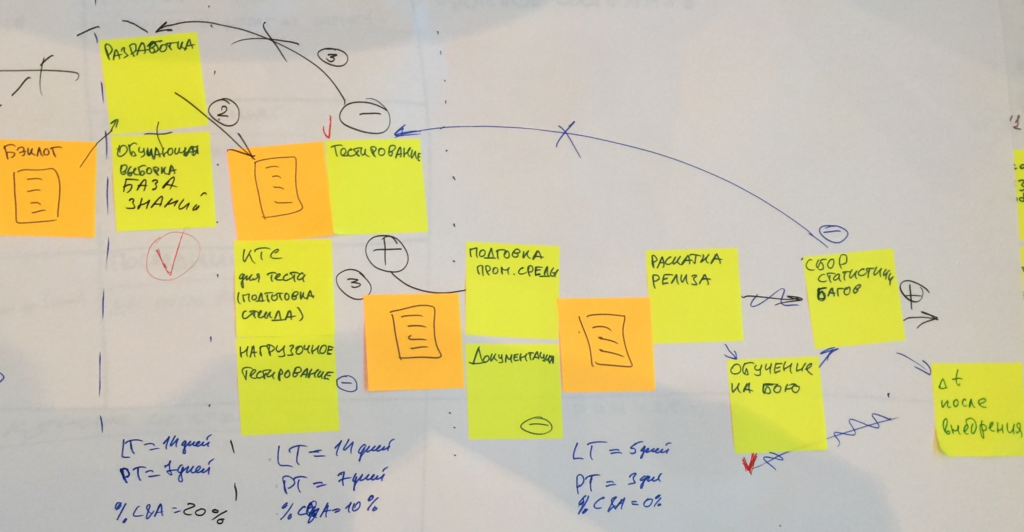
Бывают совсем сложные процессы с множеством шагов, часть из которых выполняется параллельно, c зависимостями, отчетами и ручным вмешательством. На этот этапе мы можем разве что избавиться от явных потерь (красные стикеры), этапов, которые объективно не добавляют никакой ценности клиенту, остальное — заложить в модель.

Вспомните эру компакт-дисков. Частью Delivery Pipeline'а того времени были разработка и тестирование, запись на диск, доставка поездами и фурами, продажа в магазинах, и развертывание так вообще проводилось силами самого пользователя, что выражалось в дополнительных накладных расходах на подготовку инструкций по установке и создания инсталляторов. Вот где процесс был поистине впечатляющим.
Разница между Delivery и Deployment Pipeline
Отличия могут показаться несущественными. Разница в том, отправляем мы изменения в боевую среду автоматически или в процессе присутствуют ручные операции.
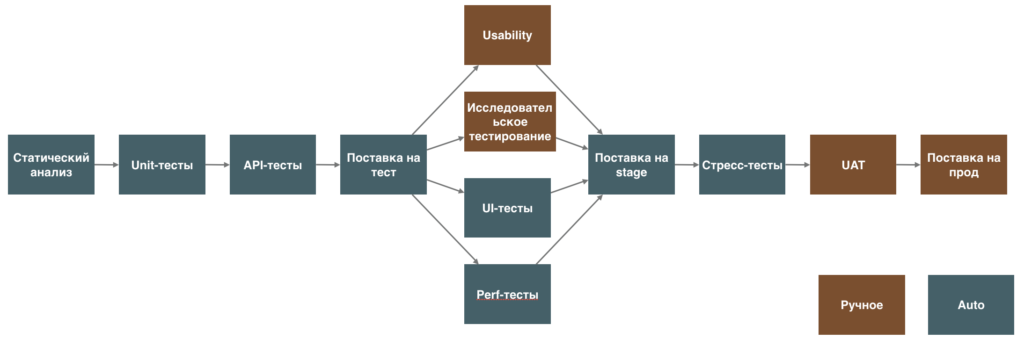
В действительности для того, чтобы перейти от Delivery к Deployment обычно нужно проделать невероятно сложную работу. Нет, можно лить все сразу на прод, даже менять код и инфраструктурные настройки «на живую», но к хорошему это приводит редко. Мы говорим о том, чтобы поставлять код, в качестве которого мы уверены, но даже если что-то произойдет — всегда иметь План Б (rollback/rollforward).
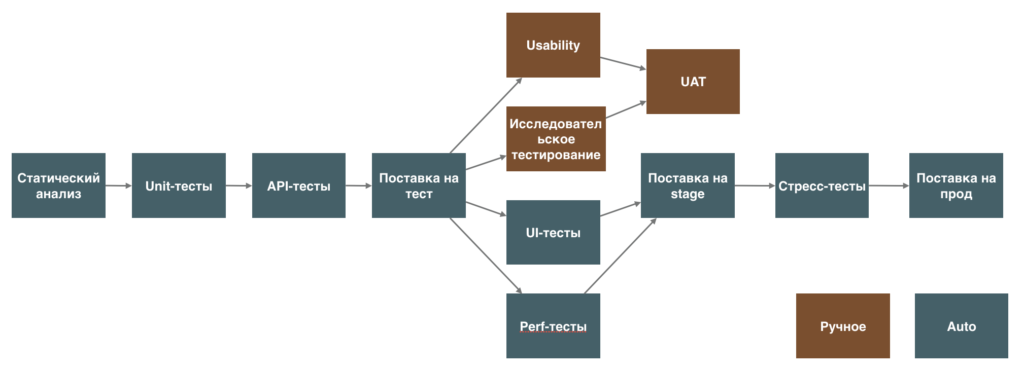
Например, придется добиться того, чтобы
- Один и тот же дистрибутив прошел все циклы тестирования
- Конфигуриация сред хранилась под контролем версий
- Был единый процесс развертывания на все среды
- Существовали автопроверки развертывания
- Cуществовала полная и прозрачная интеграция с инструментами функционального и нагрузочного тестирования; проверки безопасности
- Была реализована автоматизация развертывания на боевую среду
- Был обеспечен автоматический откат до последней рабочей версии продукта
- Была реализована сильная система наблюдаемости за системой (o11y)
- Ну и, конечно, никуда без сильной DevOps-культуры
- ……

Пунктов много, они сильно зависят от специфики продукта и текущего уровня. Разумеется, если это легаси и нет ничего вообще, ни тестов ни какой-либо автоматизации, то отдельной строкой пойдут архитектурные изменения.
Создание «скелета» Delivery Pipeline
Итак, Delivery Pipeline — это способ разделить процесс сборки на этапы. Ранние этапы — самые быстрые и должны находить наибольшее количество ошибок, в то время как поздние — значительно медленнее и чем дальше от начала они находятся, тем больше опираются на исследования .
Определение шагов Delivery Pipeline
Часто встречается мнение, что первым этапом следует точно определить все шаги сборки и заполнять шаги кодом по мере развития pipeline. Проблема в слове «точно». Да, определить стоит, но Delivery Pipeline живет и развивается вместе с продуктом, поэтому следует описывать его так, чтобы структуру и состав шагов можно было в будущем легко изменить или расширить. Те, кто сталкивался с необходимостью изменить процесс сборки в железобетонных, огромных Ant-скриптах с множественными зависимостями тасков друг от друга меня поймут.
Этап фиксации изменений
Самый первый, технический уровень Delivery Pipeline. Обычно он состоит из следующих шагов:
- Компиляция
- Выполнение Unit-тестов (на код, архитектуру и инфраструктуру)
- Статический анализ кода
После прохождения этого этапа, разработчик может продолжить разработку. Этап должен быть максимально быстрым.
Результатом компиляции является бинарный файл, используемый всеми последующими этапами. Это важно и это описано таким принципом Continuous Delivery, как «гарантия того, что единый дистрибутив пройдет все этапы поставки (Build Binaries only Once)».
Этап автоматизированного приемочного тестирования
Второй этап — функциональный. Он состоит как минимум из двух шагов:
- Выполнение автоматических функциональных/приемочных тестов
- Проверка атрибутов качества, таких как производительность, безопасность, масштабируемость.

Это более медленный этап и его цель выявить более сложные отклонения в поведении. Большая часть этого этапа направлена на исследования. Например, нагрузочное тестирование. Мы даем большую нагрузку и исследуем поведение системы под этой нагрузкой.
Этап ручного тестирования
Этот большой этап обязан выявить максимум того, что не было обнаружено автоматическими тестами. Обычно это — тестирование на окружении для исследовательского тестирования, на интеграционном окружении и UAT (User Acceptance Testing)
Этап релиза в боевую среду
Поставка продукта пользователю. Хорошим тоном является отделить поставку от релиза, тогда появляется возможность поставлять изменения на боевую среду автоматически, даже если какая-то функциональность готова не полностью, а релизить её, то есть показывать клиенту, только тогда, когда это действительно нужно.
Для этих целей можно использовать, например, Feature Toggles/Flags. Это своего рода тумблер, позволяющий включать и выключать фичу через конфигурационные параметры.
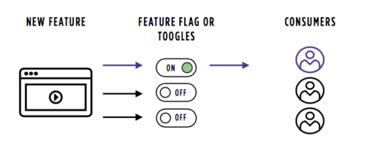
Применение Feature Flags позволяет отделить поставку от релиза и отключить функциональность на боевых серверах в случае необходимости. Это узкое определение. Более широкое — дает полный контроль над жизненным циклом отдельно взятой фичи.
Стоит предусмотреть способы включения/выключения, это могут быть:
- Командная строка
- База данных
- Админка
- API (Rest)
- Условный оператор в коде
Не все способы могут быть легко поддержаны выбранным CI/CD-инструментом.
Другой важный аспект: в случае обнаружения ошибки, мы можем выключить функциональность и исправлять ошибку в обычном режиме, не включая режим пожаротушения.
Практические советы
Каждый шаг в пайплайне должен добавлять уникальную ценность в некоторой форме. Он должен давать ценность одному или более членам команды и информировать тех, кто должен быть проинформирован.
Что можно сделать прямо сейчас?
Хороший способ начать думать в терминал пайплайна — выписать шаги, которые необходимо выполнить при срочном устранении серьезной ошибки на проде. Помните, что даже есть у вас нет непрерывной интеграции, Pipeline все равно есть, он просто состоит только из ручных операций.
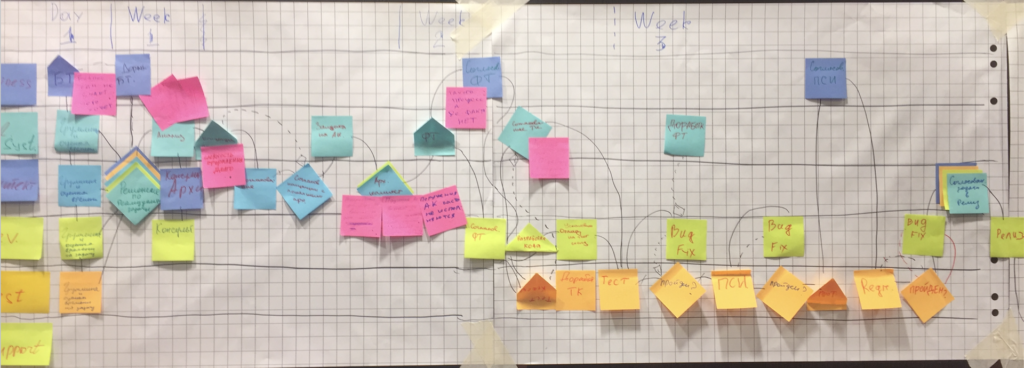
- Запишите шаги пайплайна на стикерах
- Расположите в правильной последовательности
- Пометьте ручные операции
- Посмотрите внимательно, есть ли в процессе бутылочные горлышки?
Обсуждение вокруг Pipeline’а
Вокруг визуального представления pipeline’а обычно ведутся бурные дискуссии, но если вы из тех, кто никогда этого не делал, то начать вам поможет следующий список вопросов:
- Кто должны знать о результатах каждого этапа?
- Кто должен быть уведомлен о проблемах на каждом из этапов?
- Каким образом эти люди получат уведомления?
- Какого время получения обратной связи от каждого из этапов, то есть за сколько времени после коммита вы узнаете, что есть проблемы?
- Какие вы видите способы сокращения времени до получения обратной связи?
- Есть ли шаги, которые можно выполнять параллельно?
- Есть ли зависимости от внешних систем (для тестирования требуется поднять тяжелую ERP)?
- Можете ли вы использовать тест-дублеры, стабы, моки, фейки для снижения уровня зависимостей?
- Какие ворота качества присутствуют в пайплайне? Что должно произойти, чтобы вы перешли к тестированию? Вышли в прод?
Пример из практики
Клиент решил полностью переработать мобильное приложение, так как прошлое устарело и морально и технологически. Было решено работать спринтами, постепенно развивая приложение. В конце каждого спринта должна быть полностью готова часть функциональности. Ожидалось, что к размещению в AppStore и Google Play будет готово примерно через 6 месяцев.
В первый же спринт команде была поставлена задача: выполнить полностью две конкретные пользовательские истории. Но была и вторая часть — приложение во время обзора результатов спринта должно быть установлено на мобильные телефоны участников обзора.
Команда справилась великолепно. Быстро реализовали функционал и подготовили скелет delivery pipeline от коммита до публикации с рассылкой ссылки на скачивание и установку всем заинтересованным сторонам. Плюс в том, что в первые две недели проверили pipeline на реальном приложении (те самые две пользовательские истории), собрали проблем, пока кода было не много и проблемы было легче решить, довели скелет до стабильного состояния.
Начиная со следующего спринта начали писать автотесты, точно так же, небольшими порциями. На обзоре спринта показывали не только основной функционал, но и ускоренную видеозапись прохождения автотестов. Тем самым зарабатывали политический капитал, улучшая процесс и повышая стабильность сборки одновременно.
Pipeline развивался. Спустя примерно полтора месяца стало ясно, что, не отвлекаясь на процесс поставки и развертывания, не отвлекаясь на незапланированную работу в виде дефектов (они были, но их было не много) то, что планировалось выпустить через 6 месяцев будет готово уже через четыре. Было принято решение добавить немного новой функциональности в изначальный скоуп, чтобы приложение выгодно выделялось среди остальных подобных. Что и было выполнено. Эти задачи не были обязательными, так что давления бизнеса не было и команда могла заниматься разработкой в обычном режиме и с предсказуемым уровнем качества.

1 comment
Comments are closed.