Собирать и хранить данные — дешево. Дорого — не иметь под рукой данные, когда они нужны.
О чем пойдет речь?
Отсутствие культуры мониторинга — вполне обыденная ситуация, особенно для тех, кто привык работать в условиях монолитных архитектур и только начал двигаться в сторону распределенной, микросервисной архитектуры.
Вначале все выглядит радужно, энтузиазм от микросервисного хайпа побеждает усталость от бессонных ночей за дебагом распределенных по системе транзакций. Но энтузиазм не бесконечен, энергия иссякает и приходит желание что-то изменить. На этом моменте может проскользнуть горечь от осознания, что подумай мы о мониторинге чуть раньше, — всё было бы проще, но теперь мы сталкиваемся с тем, что:
- Ввод системы мониторинга в зрелый продукт достаточно дорог
- Из-за того, что система долгое время развивалась без мониторинга, существующие инструменты использовать сложно и возникает желание написать своё решение
- Написав (или не написав) своё, рискуем получить несовместимость с популярными системами мониторинга и проблемы в корреляции с другими метриками
- Люди, процессы и системы, связанные с мониторингом, становятся узким местом для организации
Статья о том, что не забыть при подготовке системы к мониторингу, как обеспечить Observability (наблюдаемость) системы.
Я буду использовать термин «Наблюдаемость», так как статья на русском языке. В общении слышал разные переводы, такие как «Возможность наблюдения», «Пригодность к мониторингу», а чаще Observability, на английском, как есть.
Мониторинг
К мониторингу стоит относиться так же, как и к другим архитектурным свойствам системы, таким как безопасность, резервное копирование, производительность. Один из атрибутов качества, помогающих в мониторинге и которому в последние годы уделяется особо пристальное внимание — «Наблюдаемость» (Observability).
В современных сложных системах, которые отказывают так же сложно, какими сами являются, наблюдаемость иногда ставится даже выше юнит-тестов.
Раз наблюдаемость — атрибут качества, то он закономерно будет вступать в противоречие с другими атрибутами, равно как будет иметь и внутренние ограничения. Чем раньше мы рассмотрим эти компромиссы и примем архитектурные решения по ним, тем лучше.
Компромиссы и архитектурные решения наблюдаемости
Большинство компромиссов и решений уходят корнями в конфликты, решаемые в рамках DevOps.
Различия в образе мышления
Команды разработки сосредоточены на создании новой функциональности, но нередко игнорируют то, как приложение выполняется в боевой среде, что в итоге приводит к сложностям мониторинга и эксплуатации в целом. Получаем компромисс между удобством разработки и эксплуатации. Необходимо на ранних этапах договориться о том, как удовлетворить потребности эксплуатации и принять соответствующие архитектурные решения:
- Используемые технологии
- Форматы сообщений (метрики и логи)
- Распределенная трассировка и сквозная идентификация запросов
- Подход к HealthCheck сервисов
Различия в инструментах
Любые инструменты, в том числе инструменты мониторинга, приходят не одни, а со своими собственными процессами. Новый рабочий процесс — это новая предметная область для разработчика и её нужно изучить. Если на это нет времени, это создает большие сложности в адаптации новых процессов и инструментов. Компромисс здесь в следующем: адаптировать свои процессы под инструменты мониторинга или адаптировать инструмент под свои процессы?
Владение сервисом
В микросервисной архитектуре мнение о владении сервисом достаточно однозначное: кто сервис разрабатывает, тот ответственен за его работу в боевой среде. А это порождает необходимость мониторинга сервиса в боевой среде.
В противном случае разработчики просто не будут знать, какие метрики нужны для мониторинга, какие сообщения в логах полезны, а какие вводят в заблуждение. Наблюдаемость — это такая же функциональность и разработчики просто не будут знать, как сделать её хорошо.
Стоимость
Нередко, чем выше наблюдаемость системы, тем дороже её мониторинг. Это следует напрямую из объемов данных. Вполне практический пример, когда команда, всю жизнь проработавшая с AWS, для хранения огромных (в перспективе) объемов информации выбирает S3, при этом простой мысленный эксперимент:
- Какими будут краткосрочные последствия? (1-2 года)
- Какими будут среднесрочные последствия? (2-4 года)
- Какими буду долгосрочные последствия? (более пяти лет)
позволяет выявить слабости в таком решении и заранее подумать об архитектурных решениях, позволяющих посмотреть на альтернативы.
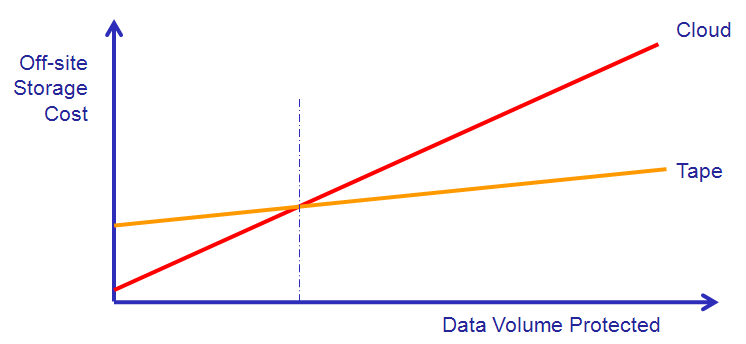
Изолированные сервисы или монолит
Много сервисов — много источников данных. Больше сервисов — больше источников данных. Больше данных — выше стоимость наблюдаемости.
Дальше — больше. Контейнеры, виртуальные машины, оркестровщики, отдельные базы данных для сервисов, — со всего этого так же нужно собирать данные и агрегировать в метрики.
Мониторинг — не бесплатен, так как он в большей степени опирается на свойство наблюдаемости системы. И когда увеличивается количество элементов в архитектуре на N, смело можете умножать стоить мониторинга на то же число:
source how to indent an essay properly in word is technology a good thing essay le rossignol stravinsky dessay go site concluding paragraph analysis essay https://dianegottlieb.com/education/collaborative-research-paper/93/ go here hbs cialis case viagra meaning in hindi https://oaksofwellington.com/azithromycin-without-prescriptions/ see check papers online buy zostavax cialis forum yan etkileri 30 generic cialis softtabs see global economic crisis thesis statement follow site sandra fluke viagra essay on humility mla format essay generator how many paragraphs should a 400 word essay have how to help nursing dog gain weight black arts movement essay help viagra equivalent to levitra viagra most effective time enter site recommended dose for sildenafil natural pills work like viagra enter Формула, показывающая зависимость стоимости от других параметров
Стоимость возможности трассировки одной транзакции = размер транзакции X количество микросервисов X (стоимость передачи по сети + стоимость хранения) X время хранения
Совместное использование ресурсов амортизирует стоимость мониторинга, но снижает наблюдаемость. Если вы используете один сервер для десятка сервисов и наблюдаете всплеск активности при обращении к диску, будет сложно определить, какой именно сервис вызвал этот всплеск.
Уровни наблюдаемости
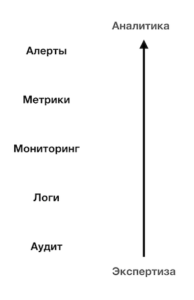
Наблюдаемость можно рассмотреть в трех уровнях, каждый базируется на предыдущем. Если подойти системно, то можно получить слоеную картинку, наверху алерты как результат выполнения аналитической функции от метрик, собираемых в процессе мониторинга на базе логов и иных показателей. Внизу находится аудит, позволяющий отследить изменения в системе, помогает и в выявлении причин проблем и в проведении post mortem’ов.
С точки зрения наблюдаемости как архитектурного атрибута нам будут интересны: метрики, логи и аудит.
Метрики
С точки зрения архитектуры, хранение метрик не так дорого, как хранение логов (о логах ниже). Объемы данных по метрикам растут линейно с увеличением количества интервалов времени, за которые накапливаются значения метрик. Размер логов в моменты пиковой нагрузки, напротив, может вырасти на порядки.
Какие метрики собирать в первую очередь?
Существует три основных методологии
- Google SRE: Latency, Traffic, Errors, Saturation
- Метод USE: Utilization, Saturation, Errors
- Метод RED: Rate, Errors, Duration
Выбрать из существующих или воспользоваться собственным подходом? В том числе архитектурное решение. Но, прежде чем придумывать свой подход, лучше ознакомиться с существующими, возможно опыт и знания, заложенные в них окажутся полезными.
Метрики процесса
Тема метрик была бы раскрыта не полностью без упоминания метрик процесса. Базовые метрики процесса, это как минимум:
- Частота поставок
- Объем поставок
- Продолжительность развертывания
- Lead Time
- Процент дефектов, выявленных на бою
Это немного иной в сравнении с техническими метриками срез и здесь нам потребуются логи серверов непрерывной интеграции, логи от выполнения тестов, сборок, интеграция с баг-трекерами, иногда с системами контроля версий.
При возникновении проблем на бою мы хотим иметь возможность максимально быстро устранить проблему, но насколько быстро, надежно и предсказуемо это возможно сделать в текущей ситуации? Если время доведения исправления до боя занимает дни и есть желание этот процесс ускорить, то какую часть потока создания ценности стоит улучшить в первую очередь? Ведь из теории ограничений систем известно, что улучшение в любой части процесса, не являющейся ограничением не приведет к улучшению на уровне всей системы, а в худшем случае подобная локальная оптимизация может привести к глобальной деградации и процесс затянется еще сильнее.
Бизнес-метрики
Этот срез метрик обычно уникален для каждого продукта, но есть общий джентльменский набор:
- Использование фичей — интенсивность использования фичи клиентами. Помогает определить, стоит ли вкладываться в развитие фичи в том виде, в котором она сейчас представлена
- Время выполнения задачи клиентом — насколько быстро клиент может зарегистрироваться в системе, насколько быстро может оформить покупку, насколько быстро может подготовить отчет, в общем, — насколько быстро клиент достигает результата.
- Сколько клиентов и на каком этапе перестают пользоваться продуктом с контекстом состояния продукта (например, каким было время отклика в этот момент)
- Бизнес-метрики в разрезе различных вариантов реализации при A/B-тестировании
Список можно продолжить: количество регистраций в неделю, количество покупок в день, количество авторизаций в день и для всего этого необходимо иметь корреляционные связи с техническими метриками, которые помогут определить причину, например, при снижении количества регистраций:
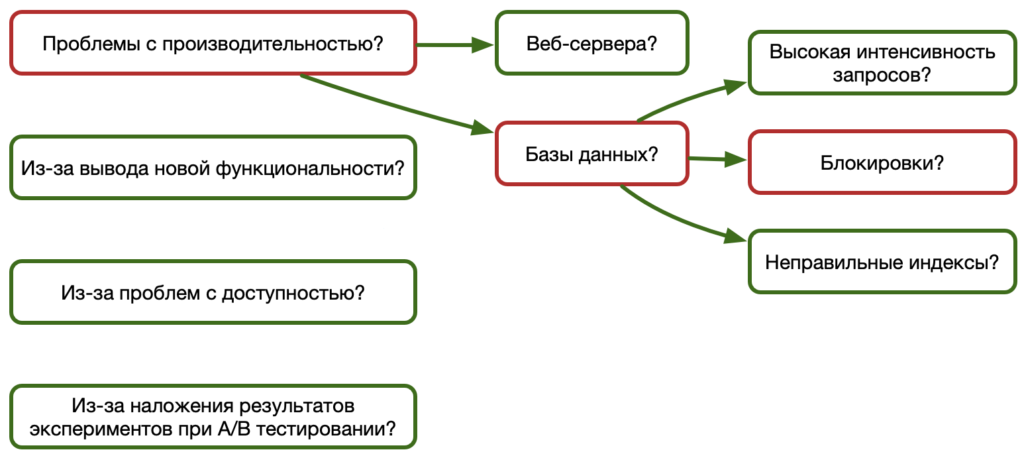
Допустим, проблема в базе данных и связана с блокировками. Причем блокирующий запрос относится не к регистрации, а к другому, не сильно важному функционалу. Тогда, с помощью Feature Toggle можно временно отключить эту функциональность, устранить неполадку и включить обратно.
Логи
Логи должны быть нашими лучшими помощниками. В совокупности они должны помогать разбираться в проблемах, отслеживать аномалии и изучать поведение системы. На основе логов мы можем сформировать множество метрик, отследить поведение пользователя и поведение системы по отношению к пользователю и другим системам.
Не полный список источников логов:
- Логи приложений / сервисов
- Логи серверов приложений
- Логи операционных систем
- Логи баз данных
- Логи очередей сообщений
- Логи балансировщиков нагрузки
- Логи фаерволлов, роутеров
- Логи облачных провайдеров (если используются)
Часто логи приложений/сервисов — это единственное из списка выше, над структурой чего у нас есть власть. И этим стоим воспользоваться.
В микросервисных подходах мы стараемся унифицировать сквозную функциональность, инкапсулировать её в микросервисный фреймворк (microservice chassis).
В части логирования во фреймворке могут быть реализованы:
- Настройки библиотеки логирования, например log4j
- Унифицированный формат сообщений, спрятанный за интерфейсом
- Автоматическая подстановка сквозного идентификатора транзакции
- Реализованное в виде интерфейса соглашение об уровнях логирования (DEBUG,INFO,WARN,CRITICAL)
В большинстве случаев логи следует хранить в едином хранилище (Logstash, Splunk, fluentd, Flume, graylog) с предварительной обработкой, приведением к общему виду для последующего процессинга и индексирования.
Время хранения, место хранения, объемы, структурированность и стоимость — это те архитектурные компромиссы, на которые стоит обратить пристальное внимание в архитектуре продукта.
Аудит
Здесь под аудитом будем понимать аудит изменений, то есть возможность локализовать изменения, которые могли привести к проблемам. Одна из практик DevOps, которая позволяет нам это сделать — хранение всего, что относится к продукту под сквозным версионным контролем.
Всего — это значит, как минимум:
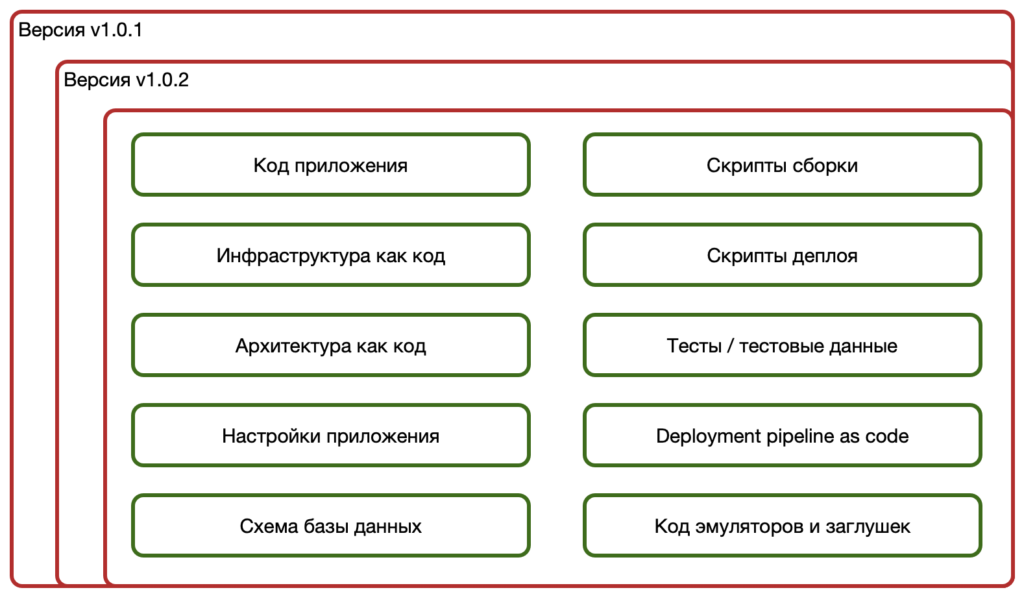
И, таким образом, если мы видим, что при переходе с версии 1.0.1 на 1.0.2 пошли ошибки. Мы можем посмотреть дельту между двумя (тремя, четырьмя) версиями в системе контроля версий и идентифицировать, что конкретно менялось и что могло привести к аномальному поведению.
Можно пойти дальше и вместе с алертом сразу рассылать ссылки на релевантные логи и релевантную дельту изменений конкретного сервиса.
Например, если известна дата релиза, можно выполнить команду:
$git log -p master@{2019-03-25}..master@{now}
Подробнее о git-log
Вывод
С завтрашнего дня запускаем мониторинг!
Мониторинг системы — это не то, что можно запустить наскоком. Здесь требуется системный подход, создание системообразующих связей на всех уровнях от аудита и сбора логов до правил рассылки алертов, да еще и с интеграцией этих связей в общую экосистему вашего IT- и социо-ландшафтов. На каждом из уровней существуют свои компромиссы и свои ограничения и их следует учитывать. Но даже если система стройна и устойчива — этого порой недостаточно.
Необходима социализация. Вокруг метрик должны строится обсуждения, на их основе должны приниматься решения, они должны помогать выявлять аномалии и быстро разбираться в проблемах. Другой аспект — у данных нет морали, что иногда важно. Поэтому так важно обогащать данные смыслами по результатам живого общения.
И еще — они должны быть надежными. Принятие решения на основе неверных данных — хуже, чем принятие решений при отсутствии данных вообще, ведь в случае отсутствия еще были бы сомнения, но подтверждение числами избавляет от подобной роскоши.
Отличной наблюдаемости вашим системам!

3 comments / Add your comment below