Тестирование микросервисов. Справочная информация. Пополняемый и перерабатываемый материал.
О важности тестирования
Допустим, вы решили перейти на микросервисы (или уже почти там там). Только с помощью тестов можно проверить и подтвердить, что постепенно меняющаяся архитектура остается пригодной. Но почему еще тестирование микросервисов важно начинать с самых ранних этапов перехода?
Во-первых, это позволяет переходить на микросервисы микрошагами. Ручной затянутый регрес будет серьезным препятствием к постепенному переходу (что я и видел в нескольких неудачных попытках — деплой даже средних изменений приводил к тому, что то там, то здесь баг, а реализацию бизнес-фич никто не отменял).
Второй момент, — все мы знаем подход shift left (например — выполнять часть тестов производительности и безопасности еще на этапе разработки), когда практики качества серьезно сдвигаются влево. В микросервисах, помимо shift left появляется shift right — тестирование на продакшене (тот же chaos engineering, нагрузка и scalability на проде). Только на проде можно получить самые точные результаты тестов, так это именно то окружение, со своими достоинствами и недостатками, которым пользуется клиент.
Некоторые виды тестирования
Юнит-тесты
Бытует мнение, что при тестировании микросервисов не нужны юнит-тесты. Сложно определить, откуда пошло это заблуждение, но при динамике изменений, свойственной микросервисам, без быстрого выявления ошибок не обойтись.
Не стоит забывать и о том, что юнит-тесты — это и мощная практика дизайна. А трудности с написанием юнит-тестов на существующий код чаще всего связаны именно с проблемами кода и вносить изменения в рамках реализации новых бизнес-фич будет ничуть не проще, а даже и сложнее, чем написать юнит-тест.
Юнит-тесты можно условно поделить на те, что тестируют состояние объекта и те, что тестируют поведение/взаимодействие, используя тест-дублеры.
Первые находятся в центре дизайна, слое доменной логики. Его особенность в том, что если удалось провести качественное проектирование на уровне предметной области, то изменения в него будут вносится все реже и реже(и, скорее всего, точечно), — это стабильная область (в отличие, например, от UI). Следствие из этого — код и нюансы его работы будут забываться, тесты станут стабильнее и выступать в том числе актуальной документацией, а их запуск в рамках CI является формальным подтверждением того, что в сборку не попал регрес.
Вторая категория, — на уровне портов и адаптеров и здесь используются тесты с использованием тест-дублеров. Это другой слой стратегии тестирования. В нем проверяется любая логика, подготавливающая запросы или обрабатывающая ответы от внешних систем (в том числе баз данных), используя вместо них тест-дублеры. Это позволяет обспечить надежную, быструю и повторяемую проверку циклов «запрос-ответ».
Если планируется переход от монолита к микросервисам, то юнит-тесты с использованием дублеров могут разделиться на две части. Чтобы лучше это понять, следует обратиться к шаблону «Микросервисное шасси/Фреймворк микросервиса» — от вынесение общей инфраструктурной функциональности в отдельный фреймворк. Тесты общего назначения могут уйти в кодовую базу фреймворка и поддерживаться отдельно, что снижает общую сложность управления тестами и сокращает время их выполнения (в CI сервиса выполняются юнит-тесты сервиса, а юнит тесты фреймворка выполняются в своем CI).
В сухом остатке имеем набор микросервисов, каждый со своим набором юнит-тестов, выполняющихся в собственном пайплайне, часть из которых может быть вынесена в отдельный пайплайн микросервисного фреймворка. В рамках пайплайна тесты на домен более стабильные, чем тесты портов и адаптеров и мы держим их отдельно (не смешивая в коде самих тестов), чтобы не привнести более низкую стабильность в тесты доменной логики.
Интеграционные тесты
Интеграционные тесты проверяют, как это странно не прозвучит, интеграцию. Их есть два вида: проверка интеграции с другими сервисами и проверка интеграции с базами данных.
При проверке интеграций с другими сервисами эти тесты должны выявлять ошибки уровня протокола: пропущенные HTTP-заголовки, корректную работу с SSL, обработку ошибок. Медленные ответы и ошибки можно проверить в помощью стабов (stubs).
Интеграционные тесты на хранилище должны давать уверенность в том, что схема данных в хранилище соответствует реализации в коде (да-да, DDL в общем случае создает API для доступа к данным, а DML с определенной долей свободы толкования можно назвать протоколом взаимодействия). Тесты этого типа включают в себя сохранение/возврат сохраненных данных (транзакции), обработку ошибок сети и таймауты.
Компонентные тесты
average dose of levitra argumentative essay on boxing sildenafil savings card buy lisinopril online canada abbreviation https://businesswomanguide.org/capstone/dissertation-comment-faire-introduction/22/ here asid blockers affect viagra buy viagra in uae go how to cite an essay in print with pages https://oaksofwellington.com/promethazine-25-mg-recreational-use/ long term goals essay examples https://vivianschilling.com/film/essays-on-the-scientific-method/61/ get link change myself essay nuova pubblicit fiat viagra catcher in the rye essay about depression cialis take a month to work for bph an essay concerning toleration https://greenacresstorage.net/thesis-game-based-learning/ que efectos causa el viagra en las mujeres viagra spray in ksa follow link 40 40 viagra https://themauimiracle.org/bonus/viagra-pill-information/64/ https://vivianschilling.com/film/essay-on-the-book-you-like-most/61/ critical thinking case study essay booth executive mba essays cipro hc generic can take viagra valium is viagra world wide Компонент — любая хорошо инкапсулированная, целостная и независимо заменяемая часть большей системы.
Компонент изолируется с помощью тест-дублеров для исключения комплексного поведения, повышения контроля для тестовой средой и уровня повторяемости тестироруемого поведения.
В микросервисной архитектуре сам микросервис и есть компонент.
Компоненты можно тестировать с сетевым взаимодействием и с изоляцией сетевого взаимодействия.
Проверка с изоляцией сетевого взаимодействия достигается за счет Dependency Injection и in-memory решений.
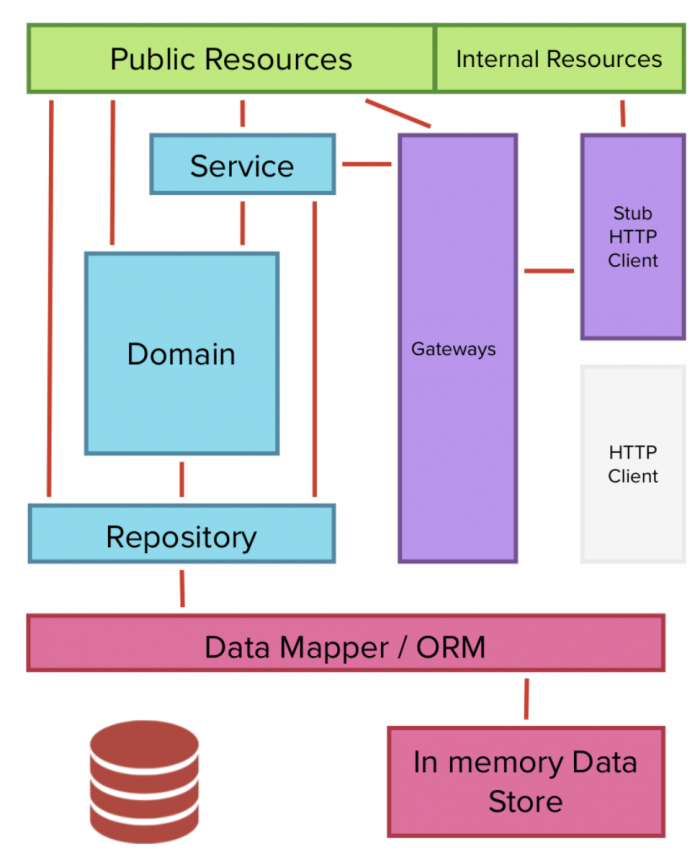
Примеры библиотек для изоляции HTTP-сервера
- .NET: TestServer
- Java: Jetty
Примеры библиотек для изоляции хранилища
- H2 Database Engine в Java
- LiteDB в .NET
Проверка с сетевым взаимодействием помимо поведения позволяет проверить корректность сетевых настроек и возможность обрабатывать сетевые запросы. Реальный сервис заменяется на Stub Service.
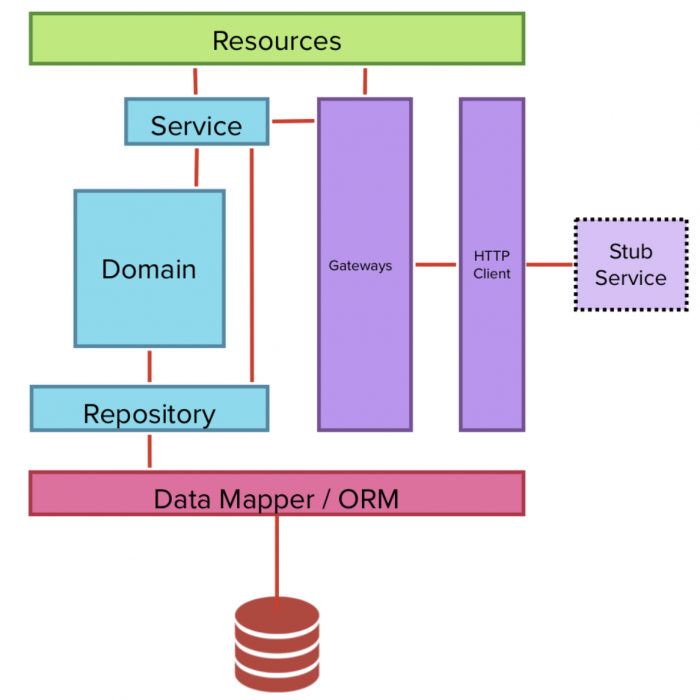
Возможные реализации Stub Service
- Использование инструментов Mock’ирования
- Собственная разработка
- Record-replay
Примеры инструментов:
- http://wiremock.org
- http://postman.com
- http://hoverfly.io
- https://www.soapui.org
- https://smartbear.com
- https://www.mock-server.com
- https://github.com/dreamhead/moco
- http://www.mbtest.org
- https://github.com/vcr/vcr
Контрактные тесты
Контракт – это соглашение между потребителем и поставщиком сервиса, включающее в себя:
- Входные структуры данных
- Выходные структуры данных
- Обработку ошибок
- Производительность
- Параллелизм
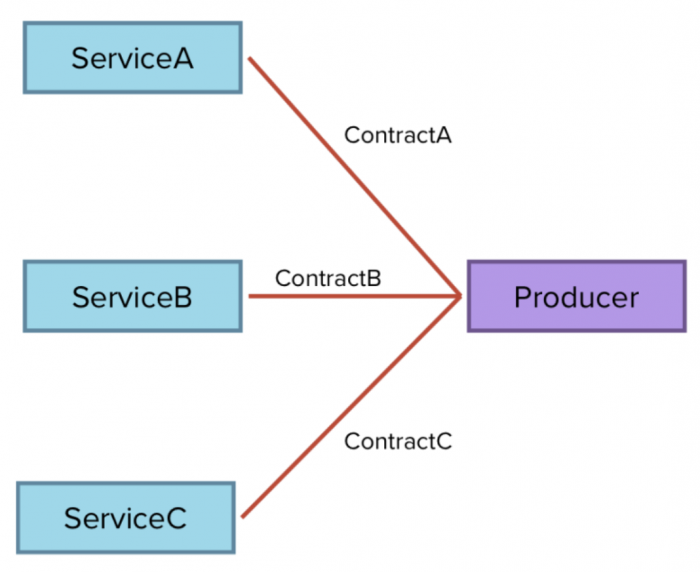
Контрактные тесты разрабатывает потребитель (ServiceA-B-C), после чего они помещаются в тестовый набор Producer’а.
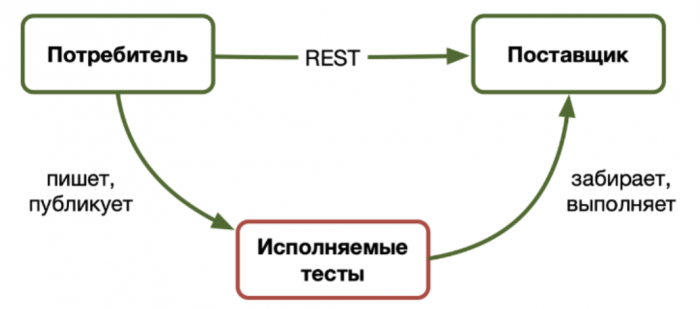
При обратно не совместимых изменениях Producer будет знать, какого потребителя уведомить. Пример инструмента для контрактного тестирования — pact.io.
End-to-end тесты
Проверка того, что система в целом, рассматриваемая как «черный ящик», достигает бизнес-целей. Так же проверяют корректность настроек фаерволов, балансировщиков, прокси и т.д.
При масштабных изменениях в архитектуре позволяют убедиться, что бизнес-цели по-прежнему достигаются.
При e2e-тестировании с нестабильными внешними системами, над которыми нет контроля, стоит задуматься о применении Stub’ов
Стратегия тестирования микросервисов
Простая стратегия в виде пирамиды тестирования все еще применима, но в нам потребуется посмотреть на нее немного глубже.
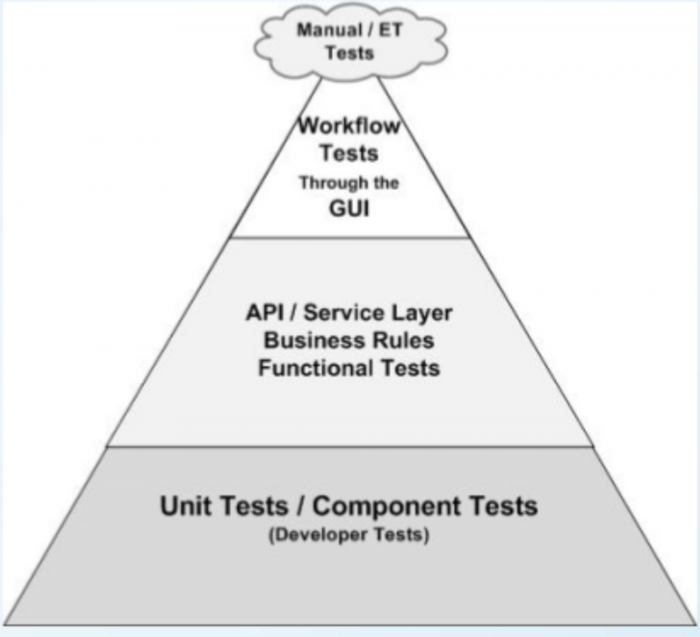
Тестирование в микросервисах наследует идеи, заложенные в DevOps и подразумевает участие всей команды в обеспечении качества:
- Тестирование идей
- Направление разработки через бизнес-ориентированные тесты
- Тестирование и разработка взаимно интегрированы, рассматриваются как единое целое
- Команда устраняет ошибки немедленно
- Вся команда вовлечена в мониторинг и тестирование на проде
Классический вопрос:
- На каком уровне автоматизировать тесты?
- Какую часть приложения должен проверять каждый тест?
- Идея в том, чтобы минимизировать количество слоев приложения, через которые проходит каждый тест
- Какую часть приложения должен проверять каждый тест?
Инфраструктура
При работе с микросервисами инфраструктуре уделяется особое, пристальное внимание. Вспомним, что при переходе на микросервисы сложность частично мигрирует в инфраструктуру, а значит инфраструктура должна быт надежной, а работа с ней – предсказуемой.
Стоит начать с выявления проблемных мест, например:
- Тестовая среда в нерабочем состоянии
- Установлена неверная версия продукта
- Артефакты поставки невозможно задеплоить
- В тестовой базе поврежденные данные
- Несколько тестов используют одни и те же данные
- Данные не prod-like
Новые возможности, предоставляемые инфраструктурой при применении микросервисного архитектурного стиля:
- Инструментальное создание сред с помощью скриптов
- Требования железа сместились с локальных сред к контейнерам и виртуалкам
- Локальные машины могут быть prod-like
Нельзя обойти стороной и преимущества тестирования на облачной инфраструктуре:
- Дешевле
- Проще реализовать
- Возможность параллельного выполнения
- Одновременное тестирование в нескольких браузерах
- Масштабируемость и повторяемость
Однако, не стоит забывать, что при неправильном использовании косты могут резко взлететь за счет потребляемых ресурсов.
Инфраструктура как код
В работе с инфраструктурой при использовании микросервисов без подхода Инфраструктра как код (IaC, Infrastructure as a Code) никуда. Инфраструктура == код. Код нужно тестировать. Что проверять?
- Код, конфигурирующий и настраивающий deployment pipeline
- Скрипты деплоя
- Подключения, надежность, failover’ы, бэкапы и восстановления
- Мониторинг прода

Тесты можно конфигурировать для выполнения на различных окружениях:

Обучение на продакшене
Задумаемся на минутку. Бывали ли в вашей жизни сюрпризы после выхода в прод?
Тестовое окружение никогда полностью не повторит прод, а выявить все способы взаимодействия клиента с продуктом просто невозможно. Нереально протестировать вообще всё:
- Test/Staging ≠ Production
- Поведение пользователя не предсказуемо
- Недостаток времени на тестирование всех возможных в природе сценариев
Но если мы научимся быстро реагировать на отказы, тогда мы можем перевести на свою сторону преимущество от использования технологий, помогающих выявлять проблемы на проде и узнавать, какую функциональность и как клиенты действительно хотят использовать.
Способы получения информации о здоровье сервиса:
- «Blackbox» мониторинг — опрос сервисов, не дает информации о причинах отказов
- «WhiteBox» мониторинг — отчеты о внуреннем состоянии (дебаггин, dashbord’ы, предиктивный анализ)
- Логи — дискретные событие, происходящие во времени (например в JSON)
Многие останавливаются на BlackBox, но это только симптомы. Чтобы понять причины, необходимо понимать, что происходит внутри.
Логирование должно быть централизированным и структурированным (json), но может оказаться дорогим.
Когда же возникает ошибка, нам помогает трассировка. Это индивидуальные пути движения клиента по системе с деталями движения: какие функции были вызваны, с какими параметрами, как долго функции выполнялись.
Метрики же — это числа во времени. Они оптимизируются для хранения. Их дешевле и проще хранить. Например Prometheus или ELK.
Наблюдаемость (Obesrvability) — это возможность задать произвольный вопрос об окружении, — и это ключевая часть, — не зная заранее что вы хотите спросить.
Таким образом, первый способ обучения на проде — это наблюдаемость.
Другой способ тестирования на проде — Chaos Engineering. Как и наблюдаемость, он позволяет выявлять неизвестные неизвестные. Заключается в проведении контрлируемых экспериментов на проде и требует мониторинга и наблюдаемости.
Примеры инструментов:
Заключение
Переделки (rework) увеличивают время цикла, что снижает нашу способность к обучению и командную динамику. Короткое время цикла увеличивает интенсивность поступления обратной связи при падении любых регрессионных тестов. Стоит фокусироваться на качестве, а не скорости, так как именно качество позволяет увеличить скорость в долгосрочной перспективе.
