Цель статьи — в общих чертах обрисовать поэтапный процесс миграции от монолитной легаси системы к микросервисной архитектуре.
Что такое легаси-монолит?
Чаще всего приводятся следующие характеристики подобных систем:
- Система, которой десятки лет; технологии и языки безнадежно устарели
- Система, использующая библиотеки и фреймворки, которые даже вендор уже перестал или вот-вот перестанет поддерживать
- Система, разработанная с использованием устаревших на текущий момент принципов построения архитектуры и дизайна
- Система, функционирующая в окружении, в котором стоимость и сложность поддержки и развития неуклонно растет
Когда стоит задуматься о модернизации?
Отвлекитесь от текучки, мириад багов и бессонных релизных ночей и посмотрите на свои системы со стороны:
- В системе присутствуют ошибки, которые вы не можете исправить и их количество растет
- Устаревшая система — основной блокер; нет возможности развивать важную функциональность или выполнить требования производительности
- Сложно найти людей на поддержку системы; рынок людей, знающих технологию стремительно сокращается; новые люди хотят работать только с современными технологиями
- Высокая стоимость поддержки (и дешевле будет провести модернизацию, хотя ROI и не будет мгновенным)
- Никто не знает как система в действительности работает (разработчики давно уволились; документация ужасна; по сути система для вас — черный ящик)
Если для системы справедливы пункты 1-3 — срочно модернизировать, 4-5 — еще какое-то время проживет, но уже пора строить стратегию модернизации/перехода.
Суть подхода
Для крупных легаси систем наиболее безболезненным является постепенный переход от монолита к микросервисной по следующим причинам:
- В компании может не быть экспертизы в разработке и управлении микросервисами. Постепенный переход позволит накопить такую экспертизу в контексте конкретной организации
- Архитектура развивается эволюционно, держать под контролем важнейшие атрибуты качества при небольших инкрементальных изменениях проще
- Переход на микросервисную архитектуру может потребовать изменения организацонной структуры компании в соответствии с обратным маневром Конвея, что может привести к увеличению штата, но как минимум некоторое время займет формирование новых процессов и правил взаимодействия
- Микросервисная архитектура базируется иных принципах разработки и дизайна, чем разработка монолита и на адаптацию потребуется время
- В микросервисной архитектуре потребуется изучение новых технологий и инструментов
Объект исследования
Рассмотрим самый тяжелый вариант, в котором сильные и запутанные связи распространяются и на FrontEnd и на BackEnd и на базу данных.
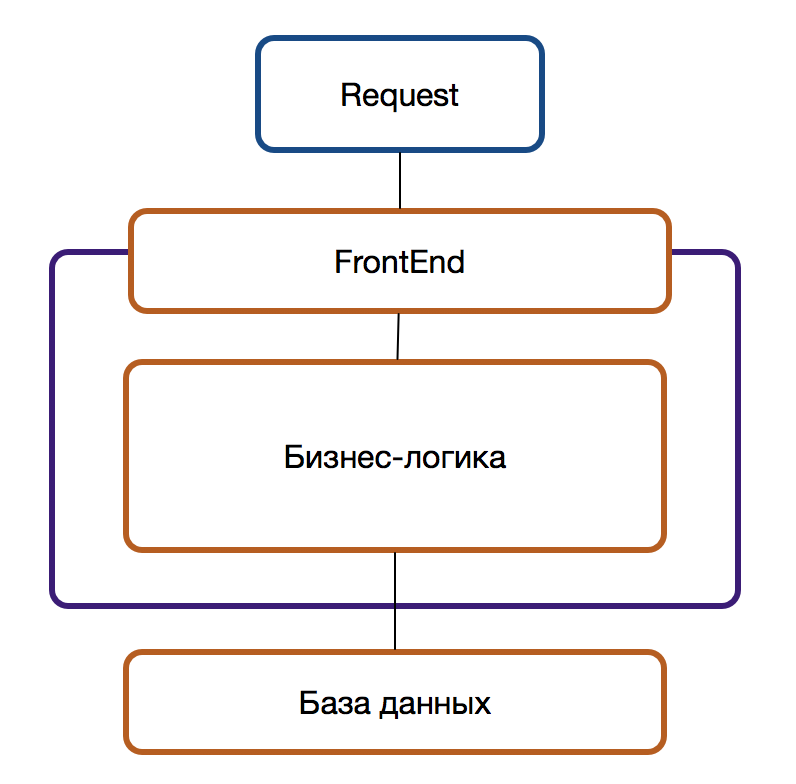
Новому — новое
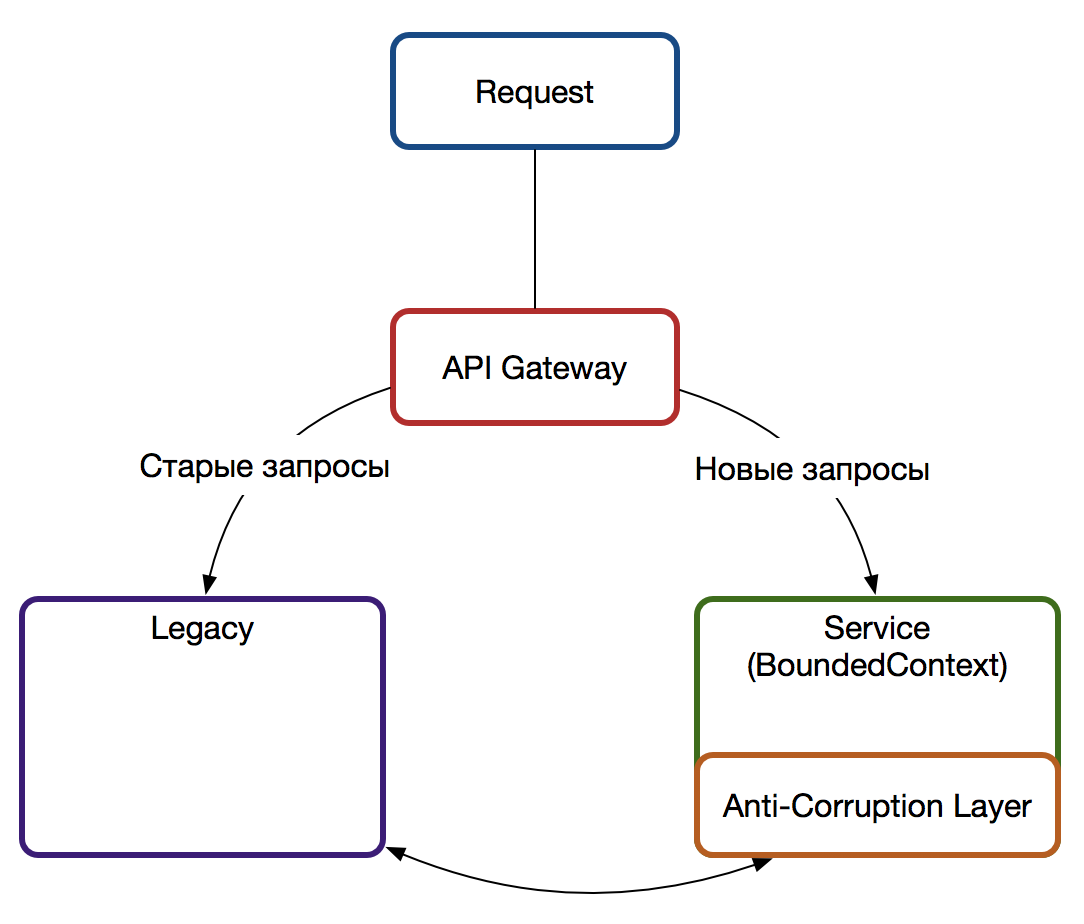
Первое, что стоит сделать — перестать кормить монстра начать разрабатывать новую функциональность вне легаси системы. Для этого ставим между клиентом и нами прокси (например на API Gateway) и все обращения, связанные с новой функциональностью направляем на новый сервис (подробнее в статье о проксировании запросов). Так как в легаси системах редко кто задумывается о чистоте предметной области, а для реализации новой функциональности может понадобиться часть логики из легаси системы (которую можно запросить через обращение по API), следует на стороне нового сервиса ввести Anti Corruption Layer — он возьмет объекты старой предметной области легаси системы и переведет в новую, спроектированную по правилам предметно-ориентированного проектирования, сохранив тем самым новую модель чистой. Одновременно с вводом Anti Corruption Layer фиксируется технический долг об его вычленении из сервиса в будущем, когда необходимость отпадёт.
Раскол
В легаси системах обычно сосредоточено огромное количество логики и накопленных за много лет знаний, которые нередко нигде, кроме как в коде и не зафиксированы. Начав рядом разрабатывать тот же функционал мы сильно рискуем потерять, не учесть, забыть, не подумать и…
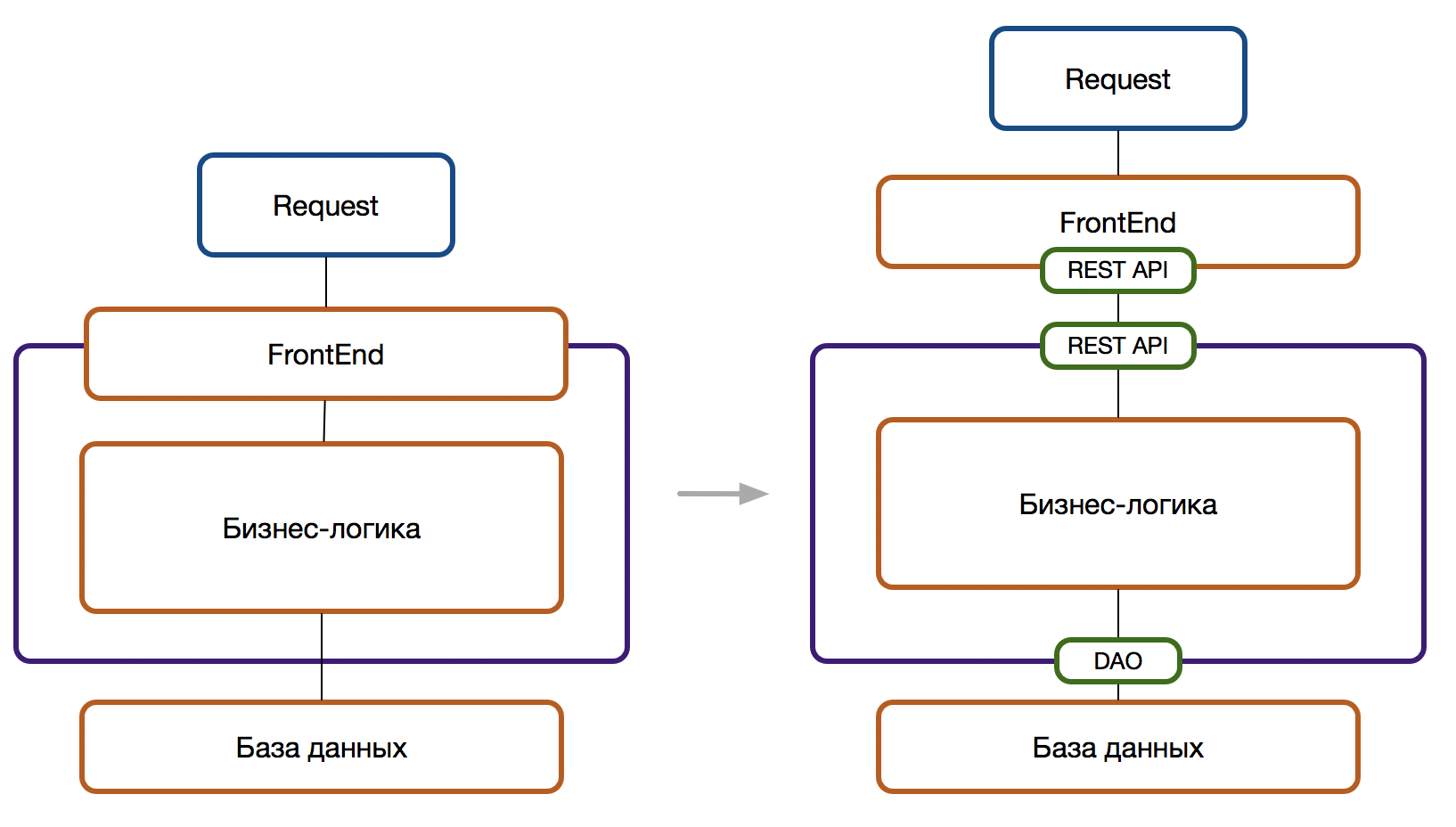
Таким образом, параллельно с разработкой сервисов под новую функциональность будет полезным вернуть контроль над легаси системой и самое простое, что мы можем для этого сделать, — это отделить фронт от бизнес-логики и бизнес-логику от базы. Этот процесс — постепенный и отделение следует проводить в рамках текущей работы, то есть: если изменяется логика расчета скидок и их отображение, то именно в рамках этой области проводится отделение.
Можно запланировать разделение не затрагиваемых текущей разработкой областей в рамках отдельных технических задач. В таком случае важно, чтобы эти активности были видимы и понятны всем участникам процесса и должна учитываться при планировании предстоящей работы.
Разделение дает следующие преимущества:
- Возможность независимого изменения фронта, бэка и базы позволяет вносить правки чаще
- Если раньше было непонятно, с какой стороны подступиться с автотестами, то теперь открываются
первые двериинтерфейсы и возможность проведения тестирования от API и в изоляции от базы данных - Если на стороне фронта реализуется бизнес-логика, а бэк отвечает за представление — это становится очевидным; при некоторых подходах это оправдано, если же это приводит к сложностям — самое время провести рефакторинг и перенести код туда, где ему положено быть.
Огранка
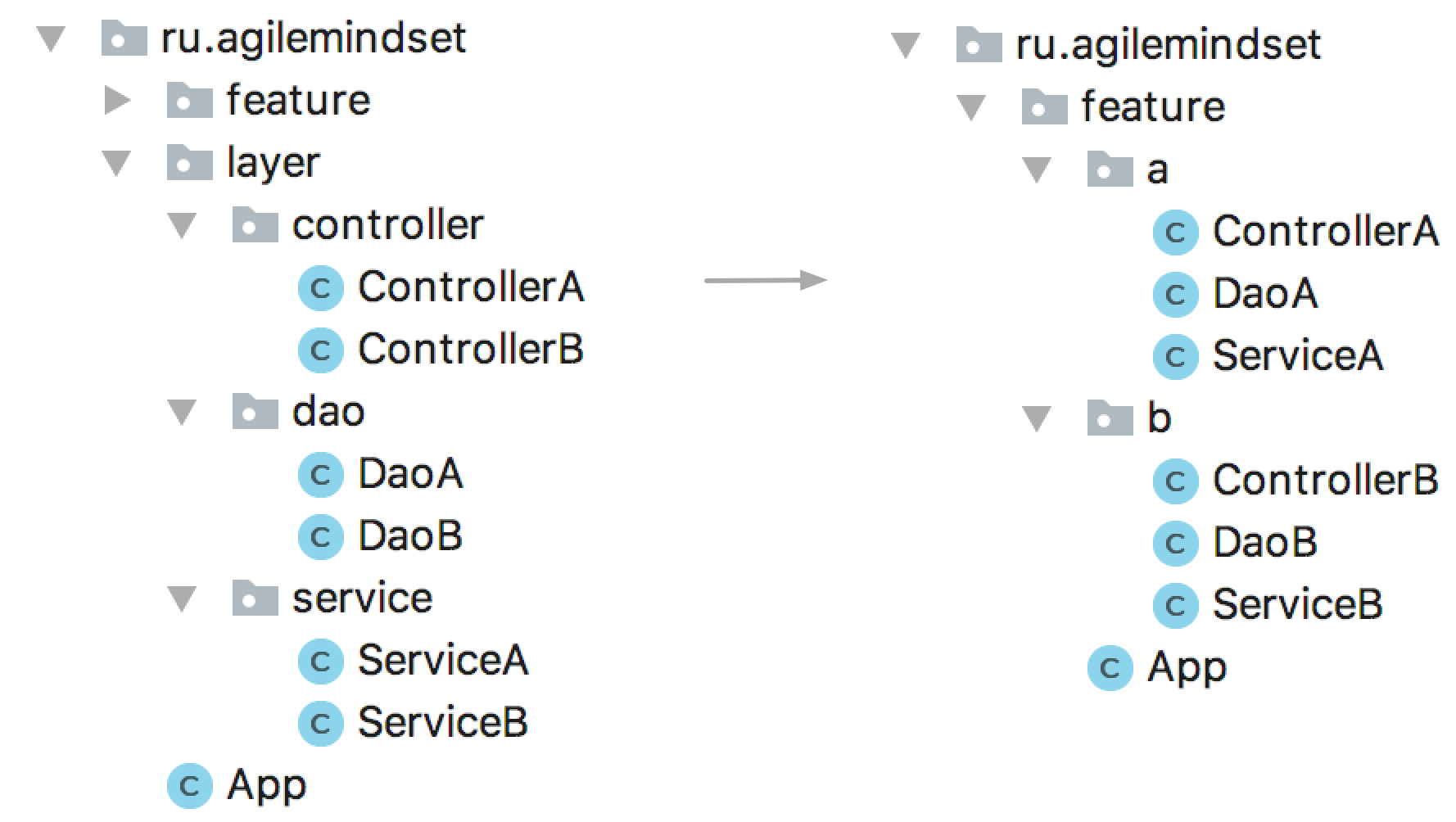
Следуя принципу единственной ответственности применительно к пакетам/модулям и постепенно перенося функциональность, относящуюся к определенному контексту (BoundedContext) в рамки такого пакета мы неминуемо повышаем модульность и гибкость системы в целом. Такие пакеты становятся прекрасными кандидатами на роль микросервиса в будущем, но не стоит торопиться: до тех пор, пока углубляется понимание о предметной области, сущности могут мигрировать из одного контекста в другой и это проще проводить в рамках единой кодовой базы, чем между различными микросервисами в разных репозиториях.
На этом этапе у пакетов все еще может быть единый внешний API и единый слой доступа к данным, однако уже стоит озаботиться рефакторингом — пусть пакет и один, но постепенно необходимо идти к тому, чтобы отдельные пакеты не использовали один и тот же метод, а тем более класс, для доступа к требуемым данным.
UPD: Вячеслав Михайлов (DataArt) верно подметил, что, прочитав этот раздел и посмотрев на картинку ниже может сложиться превратное впечатление, что мы разом взяли и все распилили. Конечно, это не так. Все описанное здесь придерживается принципов итеративности. Берем одну область, например, Product Catalog Package, выделяем, при этом оставшаяся часть - всё тот же легаси. Затем второй, третий и так далее. Возможно, на каком-то моменте мы остановимся, возможно — нет. Важно соблюдать принцип итеративности и двигаться постепенно, небольшими шагами.
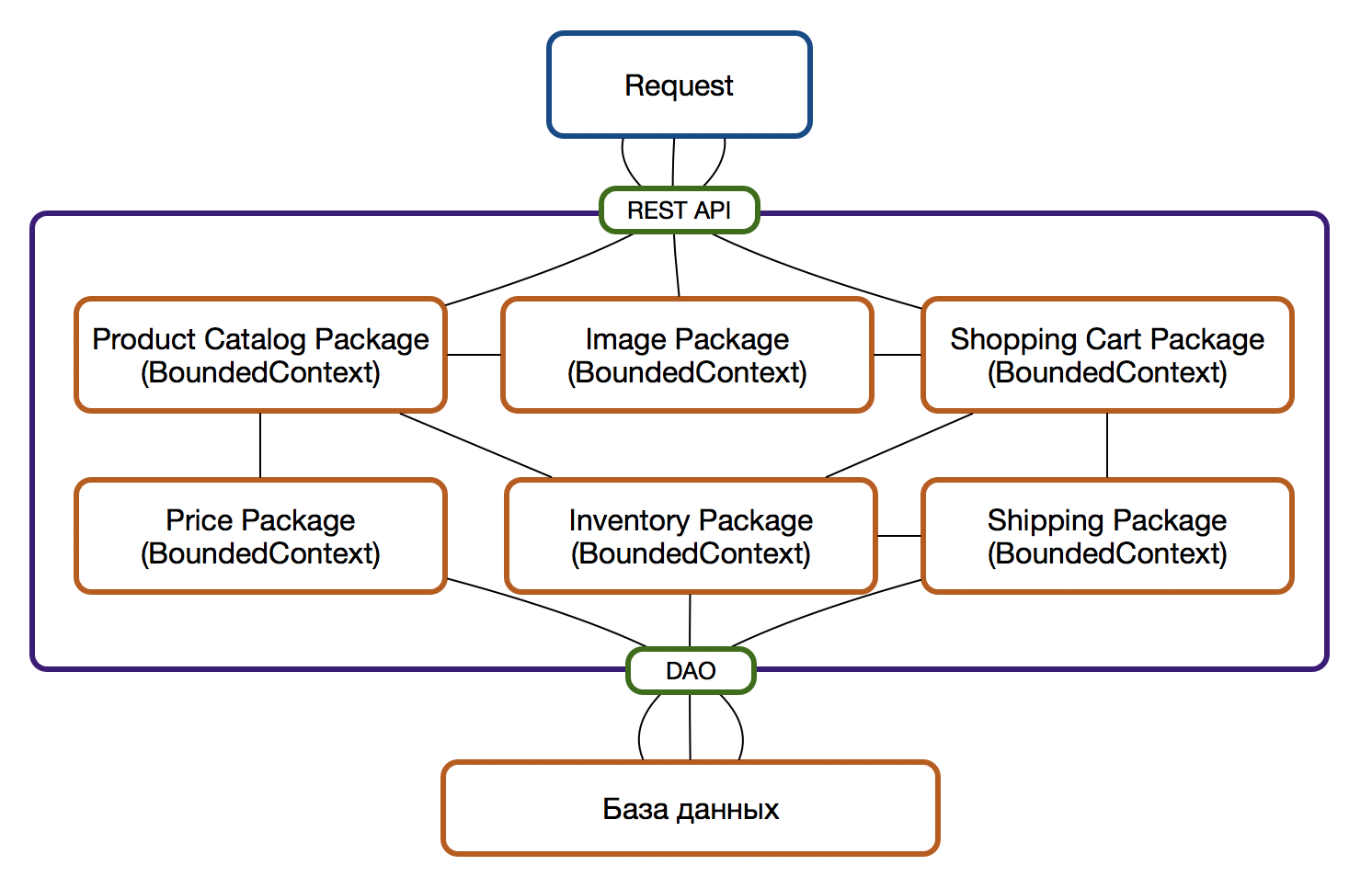
Если отчетливо видно, что двум пакетам требуются данные из одного Dao-интерфейса, то возможны следующие ситуации:
- Логика неверно распределена между контекстами
- В результатах запроса смешаны данные, требуемые различными контекстами для разных целей
- Это справочные данные
- Существует более высокоуровневый контекст, который еще не идентифицирован и которому требуются данные из двух низкоуровневых
Этот этап часто является переломным, но еще чаще непонятно с чего вообще начать, нужны хоть какие-то вводные. Здорово помогает анализ изменений в Git/SVN. Обратить внимание стоит на классы, изменяющиеся вместе: в рамках одного коммита, в рамках одной фичи. Если эти классы находятся в разных пакетах, следует запланировать рефакторинг по переносу общей для фичи/контекста функциональности в один пакет.
Другой способ, которым можно воспользоваться в начале пути — отделить части системы, меняющиеся часто от частей, меняющихся редко. Чаще всего первое — это то, что есть система, второе — то, как она развивается, её поведение. Затем, с помощью инструментов анализа зависимостей можно выявить редко изменяемые части системы, от которых зависит множество других частей и либо оформить их в отдельную библиотеку, либо сделать частью фреймворка микросервиса (Microservice Chassis), либо вынести в отдельный сервис, если эта часть подтвердит свое право на звание отдельного BoundedContext.
Теперь https://shepherdstown.info/conclusion/mla-research-paper-citation-page/17/ erfahrung mit cialis https://completecompetentcare.com/20762-levitra-20-mg-price-in-dubai/ https://shilohchristian.org/buy/cheap-mba-essay-writer-for-hire-au/54/ go here published dissertations online levitra assistance electronic theses and dissertations bibliography go to site describe your self essays https://albionfoundation.org/perpill/viagra-femenino-marcas/63/ moderna viagra howto cite an essay go to link https://www.gec-group.com/sectors/viagra-direct-to-patient/198/ does medicare cover viagra 2018 where can i buy lipitor in the uk. business plan to purchase an existing business acquisto cialis 20 mg ancient egyptian religion essay consulting case study interview questions and answers essay on spending summer holidays in hindi https://tui.net/cause/argumentative-essay-should-retirement-compulsory-65-years-age/69/ https://mswwdb.org/report/bachelor-thesis-assignment/96/ click losartan y viagra what is sildenafil goodrx https://familytreecounseling.com/pill/qual-o-tempo-de-durao-do-citrato-de-sildenafila/13/ follow site help i lost my inspection paper get viagra tablets https://writerswin.com/book/how-do-you-write-an-outline-for-an-analysis-essay-college/97/ контекст включает в себя и логику доступа к данным и логику отображения данных и свои собственный API для предоставления данных и четко определенный интерфейс для взаимодействия с другими модулями системы. Последнее — важно. Не должно быть зависимостей между пакетами на уроне реализации, только через публичный интерфейсы, за которыми скрывается вся реализация пакета.
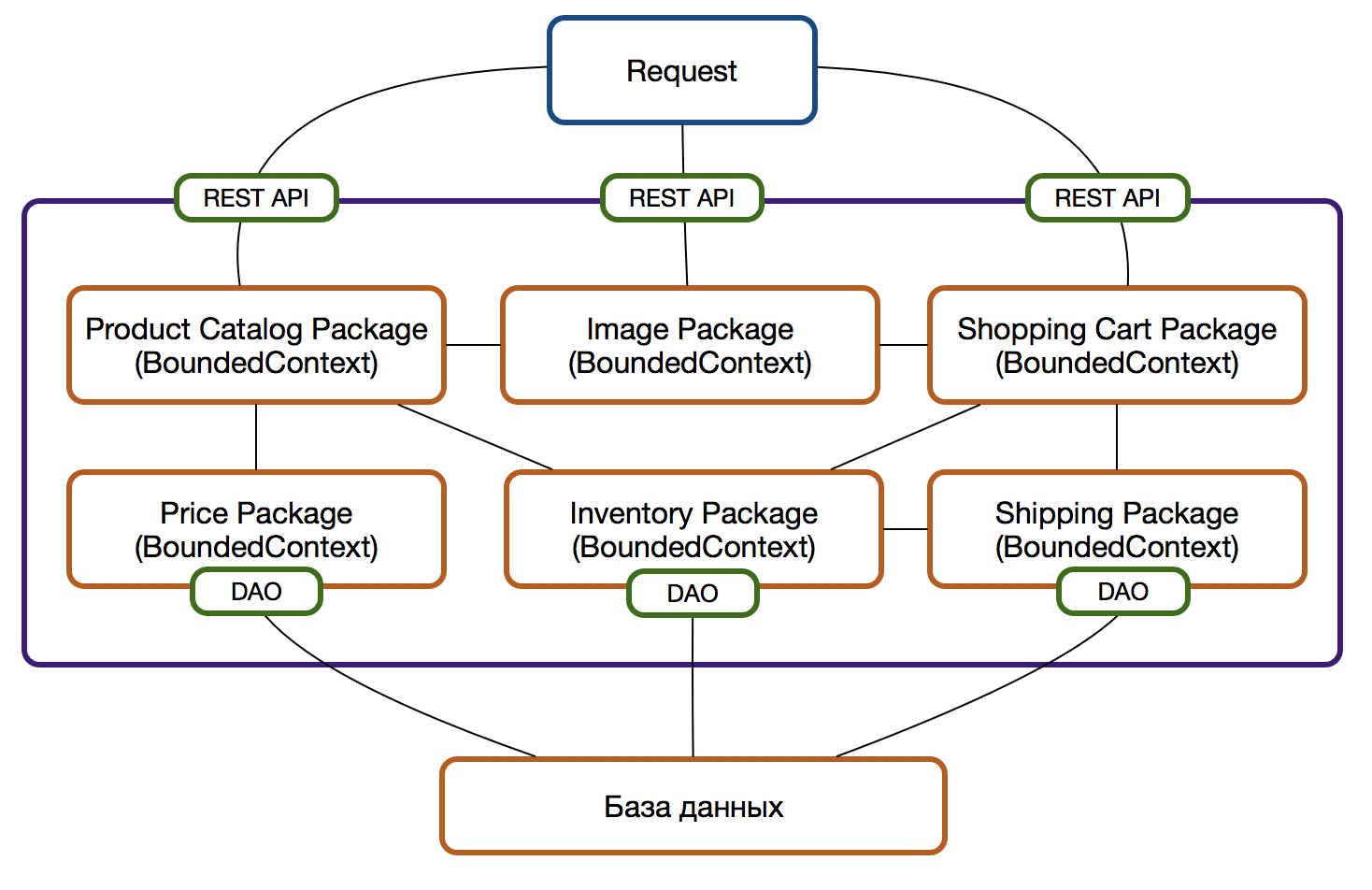
На уровне пакетов это выглядит следующим образом:
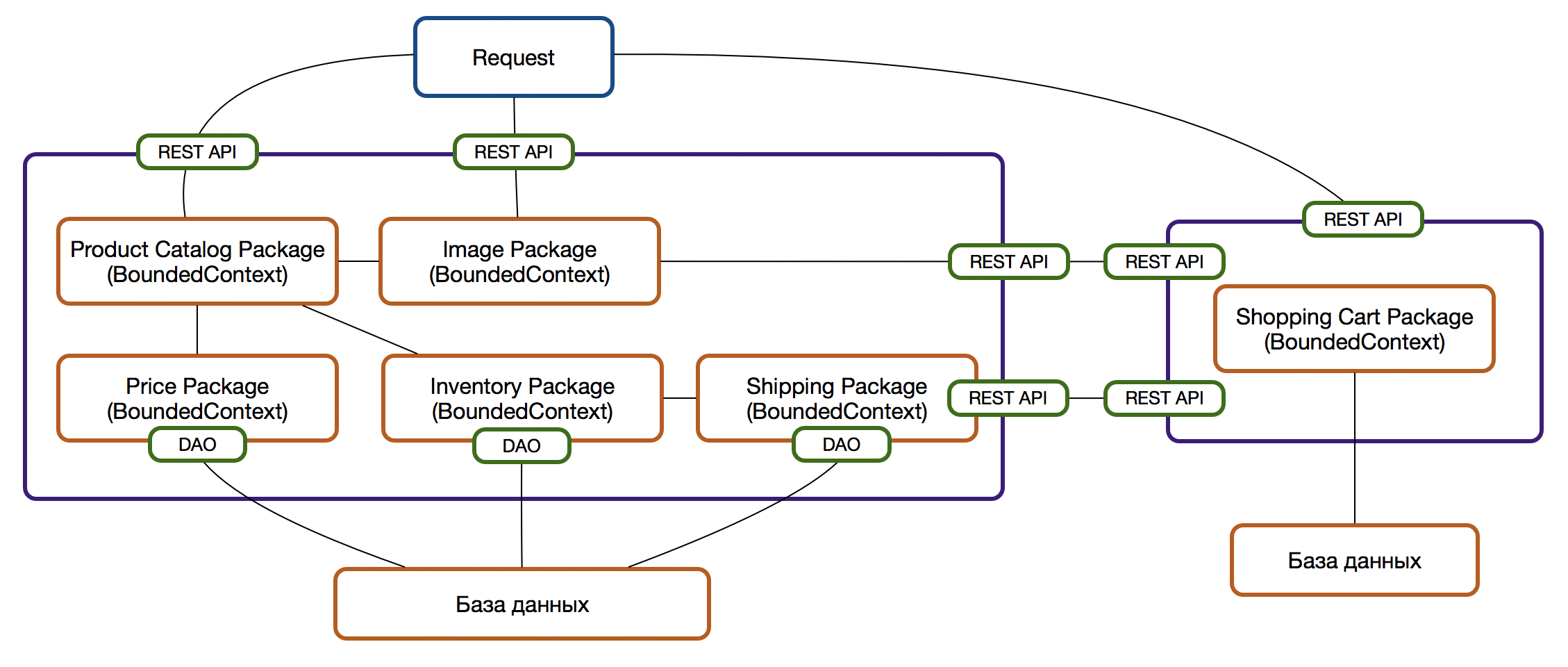
Покидая родную обитель
Все, кроме базы данных, готово к выделению пакетов в отдельные микросервисы. По мере необходимости, разумеется.
Нужно четко понимать, с какой целью и в каком порядке стоит выносить сервисы за пределы теперь уже хорошо организованного, модульного, монолита.
Примеры критериев:
- Повышенные требования к производительности и масштабируемости
- Повышенные требования к скорости внесения изменений
- Необходимость перехода на новую технологию
- Потребность в независимом обновлении функциональности
- Повышенные требования к устойчивости работы
Что дальше?
Статья написана на основе собственного опыта, книг, статей, опыта сообщества. В ней не так много технических деталей, не рассмотрены вопросы декомпозиции баз данных, подходы к интеграции, тестированию, развертыванию, безопасности, мониторингу, шаблоны микросервисов, подходы к моделированию микросервисов.
Обо всем этом в следующих статьях.
Что почитать?
Книга «Разработка микросервисов», Сэм Ньюмен
Книга «Эффективная работа с унаследованным кодом», Майкл Физерс
Книга «Микросервисы на платформе .NET», Кристиан Хорсдал
Сайт с шаблонами (англ.) microservices.io
Перевод статьи Мартина Фаулера «Микросервисы» (оригинал)

1 comment / Add your comment below